for x ∈ ( 3, 3.3e4, Int16(20), Float32(3.3e4), UInt16(9) )@show x sizeof(x) typeof(x)println()end
x = 3
sizeof(x) = 8
typeof(x) = Int64
x = 33000.0
sizeof(x) = 8
typeof(x) = Float64
x = 20
sizeof(x) = 2
typeof(x) = Int16
x = 33000.0f0
sizeof(x) = 4
typeof(x) = Float32
x = 0x0009
sizeof(x) = 2
typeof(x) = UInt16
6.1 Ganze Zahlen (integers)
Ganze Zahlen werden grundsätzlich als Bitmuster fester Länge gespeichert. Damit ist der Wertebereich endlich. Innerhalb dieses Wertebereichs sind Addition, Subtraktion, Multiplikation und die Ganzzahldivision mit Rest exakte Operationen ohne Rundungsfehler.
Ganze Zahlen gibt es in den zwei Sorten Signed (mit Vorzeichen) und Unsigned, die man als Maschinenmodelle für ℤ bzw. ℕ auffassen kann.
UInts sind Binärzahlen mit n=8, 16, 32, 64 oder 128 Bits Länge und einem entsprechenden Wertebereich von \[
0 \le x < 2^n
\] Sie werden im scientific computing eher selten verwendet. Bei hardwarenaher Programmierung dienen sie z.B. dem Umgang mit Binärdaten und Speicheradressen. Deshalb werden sie von Julia standardmäßig auch als Hexadezimalzahlen (mit Präfix 0x und Ziffern 0-9a-f) dargestellt.
x =0x0033efef@show x typeof(x) Int(x)z =UInt(32)@show z typeof(z);
x = 0x0033efef
typeof(x) = UInt32
Int(x) = 3403759
z = 0x0000000000000020
typeof(z) = UInt64
Integers haben den Wertebereich \[
-2^{n-1} \le x < 2^{n-1}
\]
In Julia sind ganze Zahlen standardmäßig 64 Bit groß:
x =42typeof(x)
Int64
Sie haben daher den Wertebereich: \[
-9.223.372.036.854.775.808 \le x \le 9.223.372.036.854.775.807
\]
32-Bit-Integers haben den Wertebereich \[
-2.147.483.648 \le x \le 2.147.483.647
\] Der Maximalwert \(2^{31}-1\) is zufällig gerade eine Mersenne-Primzahl:
usingPrimesisprime(2^31-1)
true
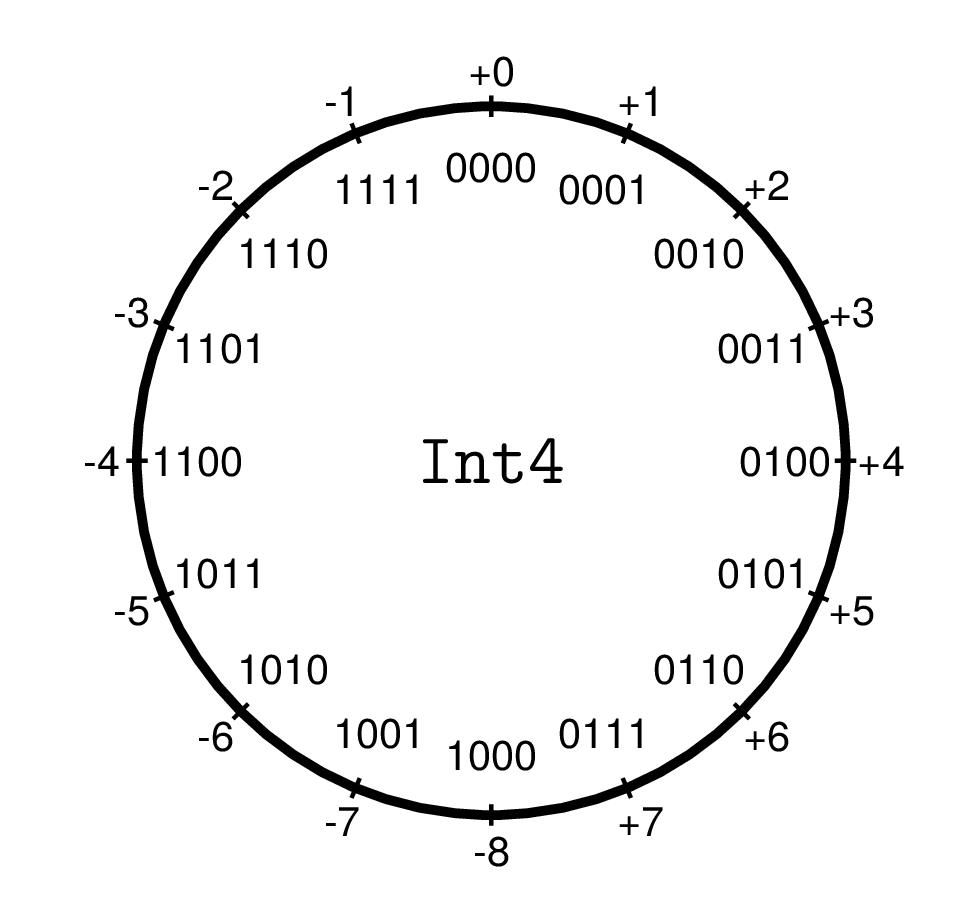
Negative Zahlen werden im Zweierkomplement dargestellt:
\(x \Rightarrow -x\) entspricht: flip all bits, then add 1
Das sieht so aus:
Eine Darstellung des fiktiven Datentyps Int4
Das höchstwertige Bit zeigt das Vorzeichen an. Sein „Umkippen“ entspricht allerdings nicht der Operation x → -x.
Wichtig
Die gesamte Ganzzahlarithmetik ist eine Arithmetik modulo \(2^n\)
x =2^62-10+2^62
9223372036854775798
x +20
-9223372036854775798
Keine Fehlermeldung, keine Warnung! Ganzzahlen fester Länge liegen nicht auf einer Geraden, sondern auf einem Kreis!
Schauen wir uns ein paar Integers an:
usingPrintffor i in (1, 2, 7, -7, 2^50, -1, Int16(7), Int8(7)) s =bitstring(i) t =typeof(i)@printf"%20i %-5s ⇒ %s\n" i t s end
Für natürliche Exponenten wird exponentiation by squaring verwendet, so dass z.B. x^23 nur 7 Multiplikationen benötigt: \[
x^{23} = \left( \left( (x^2)^2 \cdot x \right)^2 \cdot x \right)^2 \cdot x
\]
Division
Division / erzeugt eine Gleitkommazahl.
x =40/5
8.0
Ganzzahldivision und Rest
Die Funktionen div(a,b), rem(a,b) und divrem(a,b) berechnen den Quotient der Ganzzahldivision, den dazugehörigen Rest (remainder) bzw. beides als Tupel.
Für div(a,b) gibt es die Operatorform a ÷ b (Eingabe: \div<TAB>) und für rem(a,b) die Operatorform a % b.
Standardmäßig wird bei der Division „zur Null hin gerundet“, wodurch der dazugehörige Rest dasselbe Vorzeichen wie der Dividend a trägt:
Eine von RoundToZero abweichende Rundungsregel kann bei den Funktionen als optionales 3. Argument angegeben werden.
?RoundingMode zeigt die möglichen Rundungsregeln an.
Für die Rundungsregel RoundDown („in Richtung minus unendlich”), wodurch der dazugehörige Rest dasselbe Vorzeichen wie der Divisor b bekommt, gibt es auch die Funktionen fld(a,b)(floored division) und mod(a,b):
0.091471 seconds (53.71 k allocations: 2.653 MiB, 11.84% compilation time)
x = -32235833853
typeof(x) = BigInt
Durch die Just-in-Time-Compilation von Julia ist die einmalige Ausführung einer Funktion wenig aussagekräftig. Das Paket BenchmarkTools stellt u.a. das Macro @benchmark bereit, das eine Funktion mehrfach aufruft und die Ausführungszeiten als Histogramm darstellt.
usingBenchmarkTools@benchmarksum($vec_int)
BenchmarkTools.Trial: 1953 samples with 1 evaluation per sample.
Range (min … max): 2.422 ms … 3.381 ms┊ GC (min … max): 0.00% … 0.00%
Time (median): 2.524 ms ┊ GC (median): 0.00%
Time (mean ± σ): 2.550 ms ± 87.910 μs┊ GC (mean ± σ): 0.00% ± 0.00%
▃▅▆▇▆███▄▄▁▂▁
▂▂▄▅▆▇█████████████▇██▆▇▇▆▆▆▆▅▆▅▄▃▄▅▄▄▃▄▄▃▃▃▃▃▂▃▃▃▂▂▂▁▂▁▂▂ ▄
2.42 ms Histogram: frequency by time 2.83 ms <
Memory estimate: 0 bytes, allocs estimate: 0.
@benchmarksum($vec_bigint)
BenchmarkTools.Trial: 61 samples with 1 evaluation per sample.
Range (min … max): 80.020 ms … 96.473 ms┊ GC (min … max): 0.00% … 0.00%
Time (median): 81.507 ms ┊ GC (median): 0.00%
Time (mean ± σ): 82.641 ms ± 3.988 ms┊ GC (mean ± σ): 0.00% ± 0.00%
█▅ ▃▂▃
▅▇██▃███▃▇▅▁▁▁▃▁▁▁▁▁▁▁▁▁▁▃▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▁▃▁▃▃▁▁▃ ▁
80 ms Histogram: frequency by time 96 ms <
Memory estimate: 48 bytes, allocs estimate: 3.
Die BigInt-Addition ist mehr als 30 mal langsamer.
6.3 Gleitkommazahlen
Aus floating point numbers kann man im Deutschen [Gleit|Fließ]–[Komma|Punkt]–Zahlen machen und tatsächlich kommen alle 4 Varianten in der Literatur vor.
In der Numerischen Mathematik spricht man auch gerne von Maschinenzahlen.
6.3.1 Grundidee
Eine „feste Anzahl von Vor- und Nachkommastellen“ ist für viele Probleme ungeeignet.
Eine Trennung zwischen „gültigen Ziffern“ und Größenordnung (Mantisse und Exponent) wie in der wissenschaftlichen Notation ist wesentlich flexibler. \[ 345.2467 \times 10^3\qquad 34.52467\times 10^4\qquad \underline{3.452467\times 10^5}\qquad 0.3452467\times 10^6\qquad 0.03452467\times 10^7\]
Zur Eindeutigkeit muss man eine dieser Formen auswählen. In der mathematischen Analyse von Maschinenzahlen wählt man oft die Form, bei der die erste Nachkommastelle ungleich Null ist. Damit gilt für die Mantisse \(m\): \[
1 > m \ge (0.1)_b = b^{-1},
\]
wobei \(b\) die gewählte Basis des Zahlensystems bezeichnet.
Wir wählen im Folgenden die Form, die der tatsächlichen Implementation auf dem Computer entspricht und legen fest: Die Darstellung mit genau einer Ziffer ungleich Null vor dem Komma ist die Normalisierte Darstellung. Damit gilt \[
(10)_b = b> m \ge 1.
\]
Bei Binärzahlen 1.01101 ist diese Ziffer immer gleich Eins und man kann auf das Abspeichern dieser Ziffer verzichten. Diese tatsächlich abgespeicherte (gekürzte) Mantisse bezeichnen wir mit \(M\), so dass \[m = 1 + M\] gilt.
Maschinenzahlen
Die Menge der Maschinenzahlen \(𝕄(b, p, e_{min}, e_{max})\) ist charakterisiert durch die verwendete Basis \(b\), die Mantissenlänge \(p\) und den Wertebereich des Exponenten \(\{e_{min}, ... ,e_{max}\}\).
In unserer Konvention hat die Mantisse einer normalisierten Maschinenzahl eine Ziffer (der Basis \(b\)) ungleich Null vor dem Komma und \(p-1\) Nachkommastellen.
Wenn \(b=2\) ist, braucht man daher nur \(p-1\) Bits zur Speicherung der Mantisse normalisierter Gleitkommazahlen.
Der Standard IEEE 754, der von der Mahrzahl der modernen Prozessoren und Programmiersprachen implementiert wird, definiert
11 Bits für den Exponenten, also \(0\le E \le 2047\)
die Werte \(E=0\) und \(E=(11111111111)_2=2047\) sind reserviert für die Codierung von Spezialwerten wie \(\pm0, \pm\infty\), NaN (Not a Number) und denormalisierte Zahlen.
52 Bits für die (gekürzte) Mantisse \(M,\quad 0\le M<1\), das entspricht etwa 16 Dezimalstellen
Damit wird folgende Zahl dargestellt: \[ x=(-1)^S \cdot(1+M)\cdot 2^{E-1023}\]
functionprintbitsf64(x::Float64) s =bitstring(x)printstyled(s[1], color =:blue, reverse=true)printstyled(s[2:12], color =:green, reverse=true)printstyled(s[13:end], color=:red, bold=true, reverse=true)print("\n")endprintbitsf64(x)
und wir können S (in blau),E (grün) und M (rot) ablesen: \[
\begin{aligned}
S &= 0\\
E &= (10000000011)_2 = 2^{10} + 2^1 + 2^0 = 1027\\
M &= (.1011100100001)_2 = \frac{1}{2} + \frac{1}{2^3} + \frac{1}{2^4} + \frac{1}{2^5} + \frac{1}{2^8} + \frac{1}{2^{12}}\\
x &=(-1)^S \cdot(1+M)\cdot 2^{E-1023}
\end{aligned}
\]
… und damit die Zahl rekonstruieren:
x = (1+1/2+1/8+1/16+1/32+1/256+1/4096) *2^4
27.56640625
Die Maschinenzahlen 𝕄 bilden eine endliche, diskrete Untermenge von ℝ. Es gibt eine kleinste und eine größte Maschinenzahl und abgesehen davon haben alle x∈𝕄 einen Vorgänger und Nachfolger in 𝕄.
Was ist der Nachfolger von x in 𝕄? Dazu setzen wir das kleinste Mantissenbit von 0 auf 1.
Die Umwandlung eines Strings aus Nullen und Einsen in die entsprechende Maschinenzahl ist z.B. so möglich:
Das Maschinenepsilon ist ein Maß für den relativen Abstand zwischen den Maschinenzahlen und quantifiziert die Aussage: „64-Bit-Gleitkommazahlen haben eine Genauigkeit von etwa 16 Dezimalstellen.“
Das Maschinenepsilon ist etwas völlig anderes als die kleinste positive Gleitkommazahl:
floatmin(Float64)
2.2250738585072014e-308
Ein Teil der Literatur verwendet eine andere Definition des Maschinenepsilons, die halb so groß ist. \[
\epsilon' = \frac{\epsilon}{2}\approx 1.1\times 10^{-16}
\] ist der maximale relative Fehler, der beim Runden einer reellen Zahl auf die nächste Maschinenzahl entstehen kann.
Da Zahlen aus dem Intervall \((1-\epsilon',1+\epsilon']\) auf die Maschinenzahl \(1\) gerundet werden, kann man \(\epsilon'\) auch definieren als: die größte Zahl, für die in der Maschinenzahlarithmetik noch gilt: \(1+\epsilon' = 1\).
Auf diese Weise kann man das Maschinenepsilon auch berechnen:
Im Intervall \([1,2)\) liegen \(2^{52}\) äquidistante Maschinenzahlen.
Danach erhöht sich der Exponent um 1 und die Mantisse \(M\) wird auf 0 zurückgesetzt. Damit enthält das Intervall \([2,4)\) wiederum \(2^{52}\) äquidistante Maschinenzahlen, ebenso das Intervall \([4,8)\) bis hin zu \([2^{1023}, 2^{1024})\).
Ebenso liegen in den Intervallen \(\ [\frac{1}{2},1), \ [\frac{1}{4},\frac{1}{2}),...\) je \(2^{52}\) äquidistante Maschinenzahlen, bis hinunter zu \([2^{-1022}, 2^{-1021})\).
Dies bildet die Menge \(𝕄_+\) der positiven Maschinenzahlen und es ist \[
𝕄 = -𝕄_+ \cup \{0\} \cup 𝕄_+
\]
Die größte und die kleinste positive normalisiert darstellbare Gleitkommazahl eines Gleitkommatyps kann man abfragen:
Die Abbildung rd: ℝ \(\rightarrow\) 𝕄 soll zur nächstgelegenen darstellbaren Zahl runden.
Standardrundungsregel: round to nearest, ties to even
Wenn man genau die Mitte zwischen zwei Maschinenzahlen trifft (tie), wählt man die, deren letztes Mantissenbit 0 ist.
Begründung: damit wird statistisch in 50% der Fälle auf- und in 50% der Fälle abgerundet und so ein „statistischer Drift“ bei längeren Rechnungen vermieden.
Es gilt: \[
\frac{|x-\text{rd}(x)|}{|x|} \le \frac{1}{2} \epsilon
\]
6.6 Maschinenzahlarithmetik
Die Maschinenzahlen sind als Untermenge von ℝ nicht algebraisch abgeschlossen. Schon die Summe zweier Maschinenzahlen wird in der Regel keine Maschinenzahl sein.
Wichtig
Der Standard IEEE 754 fordert, dass die Maschinenzahlarithmetik das gerundete exakte Ergebnis liefert:
Das Resultat muss gleich demjenigen sein, das bei einer exakten Ausführung der entsprechenden Operation mit anschließender Rundung entsteht. \[
a \oplus b = \text{rd}(a + b)
\] Analoges muss für die Implemetierung der Standardfunktionen wie wie sqrt(), log(), sin() … gelten: Sie liefern ebenfalls die Maschinenzahl, die dem exakten Ergebnis am nächsten kommt.
Die Arithmetik ist nicht assoziativ:
1+10^-16+10^-16
1.0
1+ (10^-16+10^-16)
1.0000000000000002
Im ersten Fall (ohne Klammern) wird von links nach rechts ausgewertet: \[
\begin{aligned}
1 \oplus 10^{-16} \oplus 10^{-16} &=
(1 \oplus 10^{-16}) \oplus 10^{-16} \\ &=
\text{rd}\left(\text{rd}(1 + 10^{-16}) + 10^{-16} \right)\\
&= \text{rd}(1 + 10^{-16})\\
&= 1
\end{aligned}
\]
Im zweiten Fall erhält man: \[
\begin{aligned}
1 \oplus \left(10^{-16} \oplus 10^{-16}\right) &=
\text{rd}\left(1 + \text{rd}(10^{-16} + 10^{-16}) \right)\\
&= \text{rd}(1 + 2*10^{-16})\\
&= 1.0000000000000002
\end{aligned}
\]
Es sei auch daran erinnert, dass sich selbst „einfache“ Dezimalbrüche häufig nicht exakt als Maschinenzahlen darstellen lassen:
Bei der Ausgabe einer Maschinenzahl muss der Binärbruch in einen Dezimalbruch entwickelt werden. Man kann sich auch mehr Stellen dieser Dezimalbruchentwicklung anzeigen lassen:
usingPrintf@printf("%.30f", 0.1)
0.100000000000000005551115123126
@printf("%.30f", 0.3)
0.299999999999999988897769753748
Die Binärbruch-Mantisse einer Maschinenzahl kann eine lange oder sogar unendlich-periodische Dezimalbruchentwicklung haben. Dadurch sollte man sich nicht eine „höheren Genauigkeit“ suggerieren lassen!
Wichtig
Moral: wenn man Floats auf Gleichheit testen will, sollte man fast immer eine dem Problem angemessene realistische Genauigkeit epsilon festlegen und darauf testen:
epsilon =1.e-10ifabs(x-y) < epsilon# ...end
6.7 Normalisierte und Denormalisierte Maschinenzahlen
Die Lücke zwischen Null und der kleinsten normalisierten Maschinenzahl \(2^{-1022} \approx 2.22\times 10^{-308}\) ist mit denormalisierten Maschinenzahlen besiedelt.
Zum Verständnis nehmen wir ein einfaches Modell:
Sei 𝕄(10,4,±5) die Menge der Maschinenzahlen zur Basis 10 mit 4 Mantissenstellen (eine vor dem Komma, 3 Nachkommastellen) und dem Exponentenbereich -5 ≤ E ≤ 5.
Dann ist die normalisierte Darstellung (Vorkommastelle ungleich 0) von z.B. 1234.0 gleich 1.234e3 und von 0.00789 gleich 7.890e-3.
Es ist wichtig, dass die Maschinenzahlen bei jedem Rechenschritt normalisiert gehalten werden. Nur so wird die Mantissenlänge voll ausgenutzt und die Genauigkeit ist maximal.
Die kleinste positive normalisierte Zahl in unserem Modell ist x = 1.000e-5. Schon x/2 müsste auf 0 gerundet werden.
Hier erweist es sich für viele Anwendungen als günstiger, auch denormalisierte (subnormal) Zahlen zuzulassen und x/2 als 0.500e-5 oder x/20 als 0.050e-5 darzustellen.
Dieser gradual underflow ist natürlich mit einem Verlust an gültigen Stellen und damit Genauigkeit verbunden.
Im Float-Datentyp werden solche subnormal values dargestellt durch ein Exponentenfeld, in dem alle Bits gleich Null sind:
usingPrintfx =2*floatmin(Float64) # 2*kleinste normalisierte Gleitkommazahl > 0while x !=0 x /=2@printf"%14.6g " xprintbitsf64(x)end
NaN(Not a Number) steht für das Resultat einer Operation, das undefiniert ist. Alle weiteren Operationen mit NaN ergeben ebenfalls NaN.
0/0, Inf-Inf, 2.3NaN, sqrt(NaN)
(NaN, NaN, NaN, NaN)
Da NaN einen undefinierten Wert repräsentiert, ist es zu nichts gleich, nichtmal zu sich selbst. Das ist sinnvoll, denn wenn zwei Variablen x und y als NaN berechnet wurden, sollte man nicht schlußfolgern, dass sie gleich sind.
Zum Testen auf NaN gibt es daher die boolsche Funktion isnan().
x =0/0y =Inf-Inf@show x==y NaN==NaNisfinite(NaN) isinf(NaN) isnan(x) isnan(y);
x == y = false
NaN == NaN = false
isfinite(NaN) = false
isinf(NaN) = false
isnan(x) = true
isnan(y) = true
Es gibt eine „minus Null“. Sie signalisiert einen Exponentenunterlauf (underflow) einer betragsmäßig zu klein gewordenen negativen Größe.
Es sei noch hingewiesen auf atan(y, x), den Arkustangens mit 2 Argumenten, Er ist in anderen Programmiersprachen oft als Funktion mit eigenem Namen atan2 implementiert. Dieser löst das Problem der Umrechnung von kartesischen in Polarkoordinaten ohne lästige Fallunterscheidung.
atan(y,x) ist Winkel der Polarkoordinaten von (x,y) im Intervall \((-\pi,\pi]\). Im 1. und 4. Quadranten ist er also gleich atan(y/x)

{kind=link}