a) Es sei
b) Es sei
a) Es sei
Hinweise zur 5. Übung
1.]
Der Korrelationskoeffizient mißt die lineare Abhängigkeit von
zwei Zufallsgrößen. Nichtlineare Zusammenhänge kann man mit ihm
nicht erfassen.
a) Es sei ![]() eine symmetrische Zufallsgröße und
eine symmetrische Zufallsgröße und ![]() .
Zeigen Sie, dass
.
Zeigen Sie, dass ![]() ist.
Wie sieht dann die beste Anpassung von
ist.
Wie sieht dann die beste Anpassung von ![]() durch
durch
![]() aus?
aus?
b) Es sei ![]() und
und ![]() . Erzeugen Sie 100 Zufallszahlen
zu
. Erzeugen Sie 100 Zufallszahlen
zu ![]() und
und ![]() . Bestimmen Sie den
empirischen Korrelationskoeffizienten zwischen diesen Merkmalen und
danach die beste quadratische Anpassung.
. Bestimmen Sie den
empirischen Korrelationskoeffizienten zwischen diesen Merkmalen und
danach die beste quadratische Anpassung.
a) Es sei ![]() eine symmetrische Zufallsgröße meint, daß
eine symmetrische Zufallsgröße meint, daß ![]() =0,
dann ist
=0,
dann ist
2.]
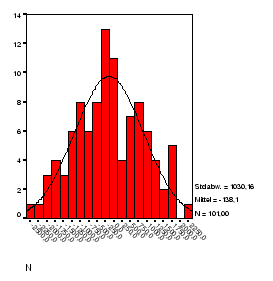
a) Erzeugen Sie mit Hilfe der Funktionen
RV.NORMAL(MW,![]() ) 100
nach N(0,1000) verteilte Zufallszahlen als Variable
) 100
nach N(0,1000) verteilte Zufallszahlen als Variable ![]() .
.
b) Erzeugen Sie die Variable Fallnummer mit der Systemvariablen $casenum.
c) Klassifizieren Sie die Variable ![]() in 10 Klassen gleicher Breite
unter der Variablen
in 10 Klassen gleicher Breite
unter der Variablen ![]() .
.
d) Berechnen und zeichnen Sie die empirischen
Verteilungsfunktionen von ![]() und
und ![]() ,
und die ''richtige'' Verteilungsfunktion der Normalverteilung N(0,1000)
in einem gemeinsamen Bild,
und
bestimmen Sie den Abstand der Verteilungsfunktionen von
,
und die ''richtige'' Verteilungsfunktion der Normalverteilung N(0,1000)
in einem gemeinsamen Bild,
und
bestimmen Sie den Abstand der Verteilungsfunktionen von ![]() und N(0,1000).
Hinweis: die Verteilungsfunktionen vieler Verteilungen stehen im Feld
und N(0,1000).
Hinweis: die Verteilungsfunktionen vieler Verteilungen stehen im Feld
![]() Berechnen unter der Abkürzung CDF.name(parameter) bereit.
Berechnen unter der Abkürzung CDF.name(parameter) bereit.
a) Zuerst sind 100 Fälle zu aktivieren, damit kann die Berechnung starten
![]() ,
Neue Variable: N,
Numerischer Ausdruck: RV.Normal(0,1000)
,
Neue Variable: N,
Numerischer Ausdruck: RV.Normal(0,1000)
b)
![]() ,
Neue Variable: Fallnummer, Numerischer Ausdruck: $casenum
,
Neue Variable: Fallnummer, Numerischer Ausdruck: $casenum
c)
Zur Klassifizierungsproblematik siehe vorangehende Serien.
Um die mühselige Einteilung in 10 Klassen per Hand zu umgehen, kann man sich
eine formalisierte Klassenzuweisung mittels Modulo-Rechnung überlegen:
1. Berechne Klasse = N - MOD(N,500) +250
2. Berechne (Falls N ![]() 0) Klasse = Klasse - 500
0) Klasse = Klasse - 500
Das erzeugt eine Klasseneinteilung in (hier 10 oder 11)
Klassen der Breite 500.
Das Aggregieren geht unter
![]() mit
mit ![]() als Aggregierungsvariable und
als Aggregierungsvariable und ![]() als
Breakvariable.
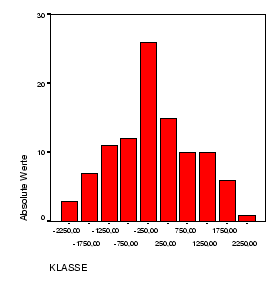
Wenn man noch die Fallzahl je Breakgruppe anklickt, erhält man in der neuen
Datentabelle die kumulierten Anzahlen je Klasse, siehe Balkendiagramm.
als
Breakvariable.
Wenn man noch die Fallzahl je Breakgruppe anklickt, erhält man in der neuen
Datentabelle die kumulierten Anzahlen je Klasse, siehe Balkendiagramm.
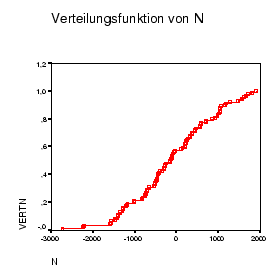
d) Verteilungsfunktionen: Zuerst sind die Variablen ![]() zu sortieren. Dann
kann wieder die empirische Verteilungsfunktion berechnet werden:
zu sortieren. Dann
kann wieder die empirische Verteilungsfunktion berechnet werden:
![]() ,
Neue Variable: Verteilung von N,
Numerischer Ausdruck: $casenum/100 .
,
Neue Variable: Verteilung von N,
Numerischer Ausdruck: $casenum/100 .
![]() gibt die empirische Verteilung.
gibt die empirische Verteilung.
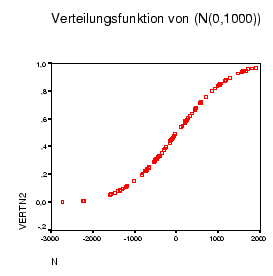
Analog zu N(0,1000): Die Variablen ![]() sind schon sortiert. Dann
sind schon sortiert. Dann
![]() , Neue Variable: Verteilung von N(0,1000),
Numerischer Ausdruck: CDF.NORMAL(N,0,1000)
, Neue Variable: Verteilung von N(0,1000),
Numerischer Ausdruck: CDF.NORMAL(N,0,1000) ![]() gibt die exakte Verteilungsfunktion.
gibt die exakte Verteilungsfunktion.
Bemerkung:
Die Verteilungsfunktionen vieler Verteilungen stehen im Feld
![]() Berechnen unter der Abkürzung CDF.name(parameter) bereit.
Berechnen unter der Abkürzung CDF.name(parameter) bereit.
Mit den Befehlsdateien spss052.sps und klass100n.sps kann diese Aufgabe gelöst werden.
3.]
Erstellen Sie in SPSS die Variable ARGUMENT ![]() mit den Werten
mit den Werten
![]() mit
mit
![]() .
Zeichnen Sie den Graph der Funktionen
.
Zeichnen Sie den Graph der Funktionen ![]() ,
, ![]() ,
, ![]() ,
, ![]() , und
, und
![]() mit dem Grafikbefehl Streudiagramm.
Es sind 201 Zeilen im SPSS-Datenfenster zu aktivieren. Mit
mit dem Grafikbefehl Streudiagramm.
Es sind 201 Zeilen im SPSS-Datenfenster zu aktivieren. Mit
![]() ,
Neue Variable: x,
Numerischer Ausdruck: ($casenum-101)/20 , ergibt sich die
Achseneinteilung von [-5,5].
,
Neue Variable: x,
Numerischer Ausdruck: ($casenum-101)/20 , ergibt sich die
Achseneinteilung von [-5,5].
Die Funktionswerte sind je:
![]() ,
,
Neue Variable: SIN
Numerischer Ausdruck: SIN(x)
Neue Variable: COS
Numerischer Ausdruck: COS(x)
Neue Variable: ARCTAN
Numerischer Ausdruck: ARTAN(x)
Neue Variable: ARCSIN
Numerischer Ausdruck: ARSIN(x)
Neue Variable: EXP
Numerischer Ausdruck: EXP(x)
In ![]() sind dann entsprechende
Variablenpaare einzubringen.
sind dann entsprechende
Variablenpaare einzubringen.
oder man verwende hier auch
![]() , da die x-Werte alle äquidistant
sind.
, da die x-Werte alle äquidistant
sind.
Beim ARCSIN stellt sich heraus, dass der Definitionsbereich nur [-1,1]
ist. Das ist korrekt! Andere Werte sind nicht zugelassen. Im Variablenfeld
stehen ansonsten ``missing values'', die der Graphikbefehl unterdrückt.
(Mit der Befehlsdatei spss053.sps kann diese Aufgabe gelöst werden.)